О проекте
Простой (но очень эффективный) многопоточный аллокатор памяти, основанный на списках освобожденных блоков.
Лучше всего подходит для приложений, выделяющих много мелких (<256 байт) блоков памяти (что обычно происходит при активном использовании stl-контейнеров), и из множества одновременно работающих параллельных потоков.
Основные характеристики
- O(1) стоимость операций выделения/освобождения блоков памяти (для блоков размером <56KB)
- Низкая фрагментация
- Практически без накладных расходов для маленьких блоков (т.к. в блоках не хранится никакого заголовка или указателя, а используется один общий заголовок размером 64 байт для всех блоков внутри 64KБ чанка)
- Высокая производительность и очень хорошая масштабируемость (практически нет блокировок, в среднем не более одной спин-блокировки на 256 операций выделения/освобождения памяти, даже в случае, когда все блоки, выделенные в одном потоке, освобождаются в другом)
Введение
Практически каждый С++ программист слышал про возможность замены аллокаторов в stl-контейнерах, но практически никогда ей не пользовался. :)
И я также, как и многие, считаю, что данная возможность является практически непригодной в реальных крупных проектах, особенно когда при использовании сторонних С++ библиотек вдруг обнаруживается, что контейнеры с различными аллокаторами просто не совместимы друг с другом.
В конце концов, для чего вообще может понадобиться переопределять стандартный аллокатор памяти в контейнерах?
Я вообще не думаю, что контроль за выделением памяти должен быть на уровне контейнера - скорее на уровне размера блоков, которые выделяет этот контейнер (напр. все узлы map<int,int> выделять из единого пула). Или на уровне пары (размер, поток). Таким образом, основное преимущество специальных аллокаторов получается в том случае, когда они выделяют блоки одинакового размера (это касается аллокаторов на основе связанного списка освобожденных блоков, т.к. основанные на пулах специальные аллокаторы (когда освобождение делается сразу всех выделенных блоков за одну операцию) использовать сложнее в общем случае, и не всегда удобно). В противном случае, память, выделенная специальным аллокатором, не будет совместно использоваться (напр. когда используются различные контейнеры, но размер выделяемых блоков одинаковый), что приведёт к избыточному расходованию памяти, а также при использовании специализированных аллокаторов могут быть какие-то нюансы, связанные с многопоточностью. В конечном счете получается, что специализированные аллокаторы создают больше проблем, чем решают.
В итоге, я подумал, что если бы выбор соответствующего пула от размера блока можно было бы перенести на время компиляции, тогда единый на всё приложение глобальный аллокатор памяти смог бы полностью избавить от необходимости в специальных аллокаторах! Идея выглядит практически нереальной, но всё-таки я решил попробовать реализовать её.
Основные принципы проектирования
1. Встраивание функций и расчеты во время компиляции.
Код функций выделения памяти должен быть настолько мал, чтобы компилятор мог встроить его в место вызова (и чтобы это не приводило к значительному росту общего объема исполняемого файла). Дополнительно, это позволит часть вычислений произвести во время компиляции, если размер выделяемого блока известен заранее, как часто и бывает в С++ коде. А именно на основе размера выделяемого блока определяется к какой группе объектов он относится. Чтобы это было возможно, расчёты на основе размера должны быть достаточно просты и опираться только на встроенные функции компилятора (никаких asm-вставок или вызовов внешних функций), а также не должно быть обращений к рассчитанным данным в памяти, а только к константам. В конце концов, исходный код необходимо компилировать с включенной оптимизацией компоновщика (LTO - опция /GL для MSVC, -flto для GCC/Clang и -ipo для ICC), чтобы все обращения к оператору new встроились в место вызова. В качестве примера, ниже приводится результат компиляции выражения "new std::array<int, 10>":
| Source Code | MSVC 2012 compiler 32-bit asm output | GCC 4.8.1 64-bit asm output |
NOINLINE void *test_function()
{
return new std::array<int, 10>;
}
void *operator new(size_t size) { return ltalloc<true>(size); }
void *operator new(size_t size, const std::nothrow_t&) { return ltalloc<false>(size); }
template <bool throw_> static void *ltalloc(size_t size)
{
unsigned int sizeClass = get_size_class(size); //рассчитывается на этапе компиляции
ThreadCache *tc = &threadCache[sizeClass];
FreeBlock *fb = tc->freeList;
if (likely(fb))
{
tc->freeList = fb->next;
tc->counter++;
return fb;
}
else
return fetch_from_central_cache<throw_>(size, tc, sizeClass);
} | mov eax,dword ptr fs:[0000002Ch]
mov edx,dword ptr [eax]
add edx,128h ;296=sizeClass*sizeof(tc[0])
mov eax,dword ptr [edx]
test eax,eax
je L1 ; вероятность перехода около 1%
mov ecx,dword ptr [eax]
inc dword ptr [edx+8]
mov dword ptr [edx],ecx
ret L1:
push 18h ; =24 (size class)
mov ecx,28h ; =40 (bytes size)
call fetch_from_central_cache<1> (0851380h)
add esp,4
ret
| mov rdx,0xffffffffffffe7a0
mov rax,QWORD PTR fs:[rdx+0x240]
test rax,rax
je L1 ; вероятность перехода ~1%
mov rcx,QWORD PTR [rax]
add DWORD PTR fs:[rdx+0x250],0x1
mov QWORD PTR fs:[rdx+0x240],rcx
ret L1:
add rdx,QWORD PTR fs:0x0
mov edi,0x28 ; =40 (bytes size)
lea rsi,[rdx+0x240]
mov edx,0x18 ; =24 (size class)
jmp <_Z24fetch_from_central_cache...>
|
| Как видно, данное выражение выполняется всего за 9 ассемблерных инструкций, а в случае GCC - даже за 7 (если не считать достаточно редкие случаи опустошения локального списка свободных блоков - один раз на 256 аллокаций для блоков до 256 байт). А вот ещё один пример - выделение большого количества блоков памяти в цикле для создания односвязного списка массивов: |
NOINLINE void *create_list_of_arrays()
{
struct node
{
node *next;
std::array<int, 9> arr;
} *p = NULL;
for (int i=0; i<1000; i++)
{
node *n = new node;
n->next = p;
p = n;
}
return p;
} | mov eax,dword ptr fs:[0000002Ch]
push ebx
push esi
mov esi,dword ptr [eax]
push edi
xor edi,edi
add esi,128h
mov ebx,3E8h ; =1000 L2:
mov eax,dword ptr [esi]
test eax,eax
je L1 ; вероятность ~1%
mov ecx,dword ptr [eax]
inc dword ptr [esi+8]
mov dword ptr [esi],ecx
dec ebx ; i++
mov dword ptr [eax],edi ; n->next = p;
mov edi,eax ; p = n;
jne L2 ; if (i<1000) goto L2 pop edi
pop esi
pop ebx
ret
L1:
... | ... L2:
mov r12,rax ; p = n;
mov rax,QWORD PTR fs:[rbx+0x258]
test rax,rax
je L1 ; вероятность ~1%
mov rdx,QWORD PTR [rax]
add DWORD PTR fs:[rbx+0x268],0x1
mov QWORD PTR fs:[rbx+0x258],rdx
L3:
sub ebp,0x1 ; i++
mov QWORD PTR [rax],r12 ; n->next = p;
jne L2 ; if (i<1000) goto L2 add rsp,0x8
pop rbx
pop rbp
pop r12
pop r13
ret
L1:
mov edx,0x19
mov rsi,r13
mov edi,0x30
call <_Z24fetch_from_central_cache...>
jmp L3 |
В этом случае компилятор соптимизировал выражение "new node;" в цикле до 6 ассемблерных инструкций!
Я думаю, что по производительности результат компиляции этого кода вполне может быть сопоставим с хорошим специализированным аллокатором, основанным на пулах.
(Но, хотя встраивание и даёт некоторые преимущества, оно не является абсолютно необходимым, и даже обычный не встроенный вызов функции ltalloc сработает очень быстро.)
2. Многопоточность и масштабируемость.
Для обеспечения высокой эффективности при работе множества параллельных потоков используется подход, аналогичный используемому в TCMalloc (я не использовал код TCMalloc, а только лишь основную идею).
Т.е., есть отдельный кэш на каждый поток, и все операции выделения памяти (кроме больших блоков >56Кб) в первую очередь пытаются получить свободный блок из этого кэша, организованного в виде простого односвязного списка освобожденных блоков на каждый диапазон размеров блоков (size class).
Если список оказался пустым, тогда из центрального списка (общего для всех потоков) выбирается сразу группа блоков (256 или меньше), помещается в локальный список потока, и один блок из этого списка возвращается приложению. Когда блок памяти освобождается, он, наоборот, добавляется сначала в список локальных блоков текущего потока, и в случае достижения определённого кол-ва блоков в этом списке (256 или менее, зависит от размера блока), весь список перемещается в центральный кэш для возможности последующего использования другими потоками.
Этот простой механизм может обеспечить достаточную масштабируемость (т.е. с достаточно небольшим числом состязаний) теоретически даже на 128-ядерной SMP-системе, если операции выделения/освобождения памяти будут разделены хотя бы 100 тактами другой полезной работы (примерно столько требуется на одну операцию перемещения группы блоков в центральный кэш или обратно). И такой подход особенно эффективен для паттерна "поставщик-потребитель", когда вся память, выделяемая в одном потоке, затем освобождается в другом.
3. Компактность размещения блоков.
В то время как многие аллокаторы хранят дополнительный указатель в начале каждого выделенного блока (т.о., напр. выделение 16 байт (или даже 13) фактически потребует 32 байта из-за требования выравнивания на 16 байт), в ltalloc хранится лишь небольшой (64 байт) общий заголовок на чанк (по умолчанию 64Кб), а все выделенные блоки хранятся непрерывно внутри чанка без каких-либо метаданных между ними, что гораздо более эффективно для маленьких блоков.
Тогда, если нет указателя в начале блока, должен быть другой способ для нахождения метаданных от данного блока. В некоторых аллокаторах для решения этой задачи используется граница sbrk, но минусы такого подхода в том, что приходится эмулировать sbrk на некоторых системах, а также в том, что память, выделенную таким способом, невозможно эффективно отдать системе после освобождения части блоков. Поэтому, я решил использовать другой подход: все большие блоки памяти (получаемые системным вызовом напрямую) всегда выровнены на размер чанка, т.о. все блоки внутри любого чанка будут не выровнены в отличие от больших блоков, и принадлежность любого блока чанку можно определить простым if (uintptr_t(p)&(CHUNK_SIZE-1)), а сам указатель на заголовок чанка легко получить через выражение (uintptr_t)p & ~(CHUNK_SIZE-1). (Подобный подход используется в jemalloc.)
Наконец, для разбивки размеров блоков на классы (size-classes) используется простой и быстрый алгоритм с округлением размера до "субстепени" двойки (2n, 1.25*2n, 1.5*2n и 1.75*2n по умолчанию, но гранулярность можно настроить, в т.ч. свести все размеры только к степеням двойки) - получается 51 класс размеров блоков до 56Кб, и накладные расходы по объему памяти (внутренняя фрагментация) не более 25%, в среднем 12%.
В качестве приятного бесплатного бонуса такой подход даёт "идеальное выравнивание" всех возвращаемых адресов блоков памяти (подробнее см. ниже).
Вопросы
1. Аллокатор ltalloc быстрее других аллокаторов памяти общего назначения?
Да, конечно! Зачем же ещё было писать свой аллокатор памяти. :)
Ну а если серьёзно, то вот сравнительная таблица производительности, основанная на простом тесте, выделяющем и освобождающем блоки памяти фиксированного размера из параллельно работающих потоков.
(Результат каждого теста указан в количестве миллионов пар операций (выделение+освобождение блока памяти размером 128 байт) в секунду на отдельный поток, т.е. для получения общего кол-ва операций необходимо умножить результат на кол-во потоков.)
| Sys. Configuration | | i3 M350 (2.3 GHz)
Windows 7 | | Core2 Quad Q8300
Windows XP SP3 | | i7 2600 (3.4 GHz)
Windows 7 | | 2x Xeon E5620 (2.4 GHz, 4 cores x 2)
Windows Server 2008 R2 | | 2x Xeon E5620 (2.4 GHz, 4 cores x 2)
Debian GNU/Linux 6.0.6 (squeeze) |
| Allocator \ Threads | | 1 | 2 | 4 (HT) | | 1 | 2 | 4 | | 1 | 2 | 4 | 8 (HT) | | 1 | 2 | 4 | 8 | 16 (HT) | | 1 | 2 | 4 | 8 | 16 (HT) |
| default | | 10.0
(6.97) | 8.4
(8.04) | 5.3
(9.53) | | 8.3
(12.61) | 1.3
(79.23) | 0.4
(218.75) | | 16.0
(10.31) | 15.2
(10.86) | 13.3
(10.26) | 8.5
(10.73) | | 11.6
(9.53) | 11.2
(9.88) | 10.8
(9.70) | 10.7
(6.21) | 5.8
(10.45) | | 14.9
(8.49) | 14.9
(8.46) | 15.3
(8.25) | 4.8
(25.48) | 0.8
(79.00) |
| nedmalloc |
| 14.2
(4.91) | 13.1
(5.15) | 7.9
(6.39) | | 15.6
(6.71) | 15.6
(6.60) | 14.0
(6.25) | | 22.4
(7.37) | 22.3
(7.40) | 19.5
(6.99) | 13.0
(7.02) | | 16.7
(6.62) | 16.6
(6.67) | 16.4
(6.39) | 10.7
(6.21) | 8.4
(7.21) | | 22.5
(5.62) | 21.3
(5.92) | 21.8
(5.79) | 19.6
(6.24) | 11.3
(5.59) |
| Hoard |
| 32.2
(2.16) | 31.3
(2.16) | 23.8
(2.12) | | 44.7
(2.34) | 44.4
(2.32) | 40.3
(2.17) | | 77.6
(2.13) | 76.3
(2.16) | 64.0
(2.13) | 43.6
(2.09) | | 57.5
(1.92) | 56.2
(1.97) | 54.6
(1.92) | 34.2
(1.94) | 31.9
(1.90) | | 31.2
(4.05) | 30.4
(4.14) | 27.4
(4.61) | 25.3
(4.83) | 16.4
(3.85) |
| jemalloc |
| 11.5
(6.06) | 11.0
(6.14) | 7.0
(7.21) | | 13.4
(7.81) | 13.3
(7.74) | 5.0
(17.50) | | 18.2
(9.07) | 18.1
(9.12) | 10.1
(13.50) | 7.4
(12.32) | | 14.1
(7.84) | 14.0
(7.91) | 6.7
(15.64) | 4.4
(15.09) | 2.9
(20.90) | | 30.1
(4.20) | 30.0
(4.20) | 30.1
(4.20) | 27.9
(4.38) | 16.2
(3.90) |
| TCMalloc |
| 15.5
(4.50) | 13.9
(4.86) | 8.9
(5.67) | | 17.0
(6.16) | 16.7
(6.17) | 15.4
(5.68) | | 34.2
(4.82) | 34.0
(4.85) | 28.2
(4.84) | 18.1
(5.04) | | 21.6
(5.12) | 20.7
(5.35) | 20.1
(5.21) | 13.6
(4.88) | 10.2
(5.94) | | 36.5
(3.47) | 36.4
(3.46) | 33.5
(3.77) | 31.4
(3.89) | 18.6
(3.40) |
| ltalloc (с выкл. LTO) |
| 31.9
(2.18) | 31.0
(2.18) | 20.8
(2.43) | | 50.9
(2.06) | 50.9
(2.02) | 44.5
(1.97) | | 81.6
(2.02) | 79.7
(2.07) | 67.4
(2.02) | 48.1
(1.90) | | 62.2
(1.78) | 62.5
(1.77) | 62.1
(1.69) | 36.3
(1.83) | 31.1
(1.95) | | 91.1
(1.39) | 91.0
(1.38) | 90.9
(1.39) | 84.8
(1.44) | 46.8
(1.35) |
| lockless |
| 43.3
(1.61) | 40.3
(1.67) | 30.2
(1.67) | | Нет результатов
(т.к. требуется Windows Vista) | | 88.7
(1.86) | 75.7
(2.18) | 75.4
(1.81) | 50.9
(1.79) | | 60.9
(1.81) | 61.1
(1.81) | 60.3
(1.74) | 39.9
(1.66) | 33.5
(1.81) | | 114.4
(1.11) | 107.6
(1.17) | 107.5
(1.17) | 102.0
(1.20) | 55.9
(1.13) |
| ltalloc |
| 69.7
(1.00) | 67.5
(1.00) | 50.5
(1.00) | | 104.7
(1.00) | 103.0
(1.00) | 87.5
(1.00) | | 165.0
(1.00) | 165.0
(1.00) | 136.4
(1.00) | 91.2
(1.00) | | 110.5
(1.00) | 110.7
(1.00) | 104.8
(1.00) | 66.4
(1.00) | 60.6
(1.00) | | 126.5
(1.00) | 126.0
(1.00) | 126.3
(1.00) | 122.3
(1.00) | 63.2
(1.00) |
| fast_pool_allocator |
| 116.5
(0.60) | 58.3
(1.16) | 12.5
(4.04) | | 152.0
(0.69) | 22.5
(4.58) | 5.6
(15.63) | | 277.8
(0.59) | 48.7
(3.39) | 25.1
(5.43) | 11.8
(7.73) | | 189.8
(0.58) | 62.0
(1.79) | 29.9
(3.51) | 3.9
(17.03) | 2.0
(30.30) | | 156.4
(0.81) | 11.5
(10.96) | 3.1
(40.74) | 1.3
(94.08) | 1.3
(48.62) |
Результаты 2x Xeon E5620/Debian в виде диаграммы:
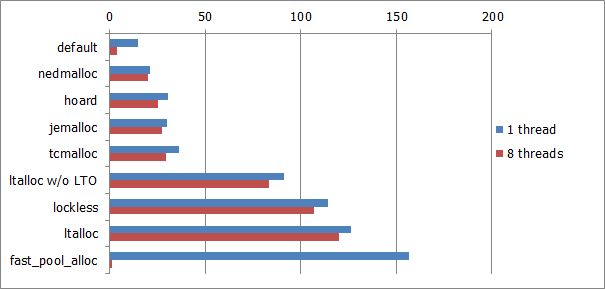
Хотя этот тест чисто синтетический и, возможно, слишком предвзятый, он позволяет достаточно точно измерить чистую стоимость операций выделения/освобождения блоков памяти, исключая влияние множества других факторов, таких как например промахи кэша (что безусловно важно в реальных приложениях, но не всегда). Тем не менее, даже этот тест может быть достаточно репрезентативным для некоторых приложений и алгоритмов (напр. использующих мало данных, целиком помещающихся в кэше).
2. За счет чего ltalloc так быстро работает?
Если коротко, то в основе лежит сверх-простой дизайн и хорошо продуманная реализация базовых функций c минимизацией условных переходов для наиболее частых случаев.
К примеру, вот так выглядит типичная реализация функции аллокации в других аллокаторах памяти:
- if (size == 0) return NULL (или size = 1)
- if (!initialized) initialize_allocator()
- if (size < some_threshold) (для проверки что блок достаточно маленького размера)
- if (freeList) {result = freeList, freeList = freeList->next}
- if (result == NULL) throw std::bad_alloc() (в реализации оператора new)
Но в случае вызова оператора new, перегруженного через ltalloc, в среднем будет всего лишь одна условная инструкция - на основе п.4 (которая к тому же не приведёт к переходу в 99% случаев), в то время как остальные проверки будут делаться только по мере необходимости в редких случаях.
rmem
3. Как часто аллокатор возвращает память системе автоматически?
Ну в общем-то, никогда не возвращает (не считая больших блоков, запрашиваемых напрямую у системы).
Но всегда есть возможность сделать это вручную вызовом функции ltalloc_squeeze(), который можно делать в любое время (в т.ч. в отдельном потоке), и который практически не оказывает никакого влияния на производительность операций выделения/освобождения памяти в других потоках (кроме, очевидно, необходимости повторного получения памяти у системы при новых аллокациях). Кроме того, эта функция освобождает столько кэшированной аллокатором памяти сколько возможно - не только в "конце выделенной области" (как реализовано в malloc_trim и некоторых других аллокаторах).
Я не хотел делать эту процедуру автоматической, т.к. она сильно завязана на паттерн выделения памяти приложением (например., можно представить серверное приложение, которое периодически (раз в минуту напр.) должно обрабатывать какой-то тяжелый запрос, настолько быстро насколько возможно, и после обработки все выделенные блоки освобождаются - и если автоматически возвращать всю эту память системе в этом случае, то может несколько снизиться производительность обработки последующих запросов, т.к. это каждый раз будет требовать выделения памяти у системы). Кроме того, я очень не люблю всякие настраиваемые параметры пороговых значений, т.к. их обычно трудно настроить оптимально для большинства случаев использования, и в каких-то ситуациях производительность непременно будет значительно проседать. К тому же, автоматическое освобождение потребует дополнительных проверок в базовых функциях выделения/освобождения памяти (хотя и не обязательно на каждый вызов, но тем не менее когда-то они должны отрабатывать), и что более важно, такая процедура достаточно затратная, т.е. предпочтительно всё-таки вызывать ltalloc_squeeze асинхронно. В общем, поэтому я решил оставить только ручной вариант запуска процедуры возврата системе памяти от освобожденных блоков. Эту процедуру можно вызывать в наиболее подходящие моменты в зависимости от приложения (например, во время неактивности пользователя, либо сразу после закрытия вложенного окна/вкладки и т.д.).
Но если всё-таки хочется, чтобы очистка работала автоматически, то можно просто запустить отдельный поток, который будет периодически вызывать ltalloc_squeeze(0). Вот вариант реализации в одну строку на С++11:
std::thread([] {for (;;ltalloc_squeeze(0)) std::this_thread::sleep_for(std::chrono::seconds(3));}).detach();4. Почему аллокатор не предоставляет никакой статистики по выделенным блокам памяти?
Потому, что это дополнительные расходы, и я не вижу большого смысла в подобного рода вещах в таком простом аллокаторе (и он предназначен для максимально высокой производительности выделения памяти, с минимумом проверок).
В любом случае, для опционального включения такой статистики должна быть какая-то константа препроцессора, т.о. можно просто взять более подходящую реализацию malloc-а, предоставляющую всю необходимую статистику (а возможно также ещё и отладочные проверки и поиск утечек памяти), и включать её только при необходимости (в отладочных целях) при установленной константе препроцессора, напр. примерно таким образом:
#ifdef ENABLE_ADDITIONAL_MEMORY_INFO
#include "some_malloc.cxx"
#else
#include "ltalloc.cc"
#endif
5. Почему нет отдельной функции аналога aligned_alloc для выделения выровненных блоков памяти?
Просто потому, что она не нужна! :)
Дело в том, что одной из особенностей аллокатора является то, что возвращаемые адреса блоков всегда "идеально выравнены" в соответствии с запрашиваемым размером, т.е. выравнивание составляет не менее pow(2, CountTrailingZeroBits(size)) байт. Напр., 4-хбайтные блоки всегда выровнены на 4 байта, 24-хбайтные - на 8 байт, 1024-хбайтные - на 1024, 1280 - на 256 и т.д.
(Учтите, что в C/C++ размер структуры всегда кратен размеру её наибольшего базового элемента, т.е. sizeof(struct {__m128 a; char s[4];}) = 32, а не 20 (16+4) ! Т.о., для любой возможной структуры S оператор "new S" всегда возвращает указатель, выровненный соответствующим образом.)
Т.о., если вам требуется выделить область памяти, выровненную на 4Кб, тогда просто подкорректируйте необходимый размер как (size+4095)&~4095 перед вызовом ltalloc (или new char). (К слову, в функцию aligned_alloc согласно стандарту С11 значение размера нужно передавать уже кратным параметру выравнивания, т.о. ltalloc() можно безопасно вызывать прямо вместо aligned_alloc(), т.е. даже без указания значения выравнивания, т.к. оно не требуется.)
Но, если честно, "идеальное выравнение" работает не для любых размеров блоков, а только не превышающих размер чанка (который равен 64Кб по умолчанию, т.е. в общем-то, это ограничение не должно быть проблемой). Адреса блоков большего размера выравнены только на размер чанка, и не более.
Вот полный список всех диапазонов размеров блоков и соответствующего им выравнивания:
| Запрашиваемый размер | Выравнивание | | Запрашиваемый размер | Выравнивание | | Запрашиваемый размер | Выравнивание | | Запрашиваемый размер | Выравнивание |
| 1..4 | 4 | | 81..96 | 32 | | 769..896 | 128 | | 7169..8192 | 8192 |
| 5..8 | 8 | | 97..112 | 16 | | 897..1024 | 1024 | | 8193..10240 | 2048 |
| 9..12 | 4 | | 113..128 | 128 | | 1025..1280 | 256 | | 10241..12288 | 4096 |
| 13..16 | 16 | | 129..160 | 32 | | 1281..1536 | 512 | | 12289..14336 | 2048 |
| 17..20 | 4 | | 161..192 | 64 | | 1537..1792 | 256 | | 14337..16384 | 16384 |
| 21..24 | 8 | | 193..224 | 32 | | 1793..2048 | 2048 | | 16385..20480 | 4096 |
| 25..28 | 4 | | 225..256 | 256 | | 2049..2560 | 512 | | 20481..24576 | 8192 |
| 29..32 | 32 | | 257..320 | 64 | | 2561..3072 | 1024 | | 24577..28672 | 4096 |
| 33..40 | 8 | | 321..384 | 128 | | 3073..3584 | 512 | | 28673..32768 | 32768 |
| 41..48 | 16 | | 385..448 | 64 | | 3585..4096 | 4096 | | 32769..40960 | 8192 |
| 49..56 | 8 | | 449..512 | 512 | | 4097..5120 | 1024 | | 40961..49152 | 16384 |
| 57..64 | 64 | | 513..640 | 128 | | 5121..6144 | 2048 | | 49153..57344 | 8192 |
| 65..80 | 16 | | 641..768 | 256 | | 6145..7168 | 1024 |
Блоки размером более 57344 байт выделяются напрямую у системы (фактически выделяемая память кратна размеру страницы (4Кб), но расход виртуальной памяти кратен 65536 байт).
6. Почему большие блоки никак не кэшируются, а всегда запрашиваются напрямую у системы?
Фактически, это не даст значительного повышения производительности для практических задач, т.к. простые тесты показывают, что выделение даже 64Кб напрямую через VirtualAlloc или mmap быстрее (в 2-15 раз в зависимости от системы), чем простое зануление выделенного блока памяти через memset (кроме первого раза, который занимает в 4-10 раз больше из-за необходимости размещения страниц в физической памяти системой при первом доступе к страницам). Но очевидно, для бОльших размеров накладные расходы на системный вызов и переход в ядро будут ещё менее заметны. Однако, если для вашего приложения это имеет значение, то просто увеличьте значение параметра CHUNK_SIZE до желаемого уровня (однако хочу заметить, что в реальных приложениях рост требуемых объемов памяти идёт больше на уровне количества выделяемых блоков, а не их размера (напр., был 1 млн. записей - стало 2 млн., аналогично при добавлении в структуру новых объектов типа std::string и пр.; в то время как напр. средняя длина самих строчек увеличивается значительно реже), т.о. текущие значения параметров можно считать одинаково подходящими как для пользовательских приложений, так и для серверных).
Использование
Для подключения ltalloc к вашему C++ приложению достаточно просто добавить файл ltalloc.cc к списку исходных файлов проекта. В нём переопределяются глобальные операторы new и delete, что является полностью совместимым с С++ стандартом решением для замены практически всех аллокаций памяти в С++ приложениях (т.к. stl контейнеры по умолчанию используют глобальный оператор new). Но если этот способ не подходит для вашего приложения, то есть и другие варианты подключения. Фактически, исходный файл ltalloc.cc написан на C (и переопределение операторов new/delete отключается автоматически, если идентификатор __cplusplus не опередён), и т.о. он может быть скомпилирован как С, так и С++ компилятором.
GNU/Linux
- gcc /path/to/ltalloc.cc ...
- gcc ... /path/to/libltalloc.a
- LD_PRELOAD=/path/to/libltalloc.so <appname> [<args...>]
Для использования вариантов 2 и 3 необходимо построить libltalloc:
hg clone https://code.google.com/p/ltalloc/
cd ltalloc/gnu.make.lib
make
(после этого файлы libltalloc.a и libltalloc.so будут созданы в текущей директории)
И при использовании этих вариантов (2 или 3) все вызовы malloc/free (а также calloc, posix_memalign и т.д.) будут проходить через ltalloc.
Также необходимо заметить, что при использовании опций -flto и -O3 с вариантом 2 компилятор GCC не будет встраивать вызовы функций malloc/free, если не добавить также опции -fno-builtin-malloc и -fno-builtin-free (однако, это лишь незначительное замечание по производительности, и совсем не обязательно для корректной работы).
Windows
К сожалению, под Windows не существует простого способа переопределения всех вызовов crt-функций malloc/free, и на данный момент есть только один простой способ замены практически всех аллокаций памяти в С++ приложениях - через перегрузку глобальных операторов new/delete (для этого, просто добавьте файл ltalloc.cc в ваш проект).
ltalloc был успешно собран компиляторами MSVC 2008/2010/2012, GCC 4.*, Intel Compiler 13, Clang 3.*, впрочем его исходный код очень простой, и может быть с лёгкостью портирован для компиляции любым другим компилятором C или C++ с поддержкой thread-local переменных. (Замечание: в некоторых сборках MinGW есть проблема с emutls и порядком вызова деструктора потока (все thread-local переменные удаляются до его вызова), и завершение любого потока может приводить к крашу.)
